004.Spark Machine Learning
Spark Machine Learning
引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.4.5</version>
</dependency>
相关系数矩阵相关系数矩阵(i行,j列)的元素是原矩阵i列与j列的相关系数
#身高与体重的相关系数矩阵
SparkSession spark = SparkSession.builder().appName("ml test")
.master("local[*]")
.getOrCreate();
List<Row> data = Arrays.asList(
RowFactory.create(Vectors.dense(17
2020-04-15
spark

003.Spark Streaming/Structured Streaming
spark streaming-hello worldnote:http://spark.apache.org/docs/latest/streaming-programming-guide.html
引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.5</version>
</dependency>
安装 Netcat 下载地址:http://netcat.sourceforge.net/
解压-启动
$ nc -lk 9999
example
SparkConf conf = new SparkConf().setAppName("spark streaming").setMaster("local[*]");
JavaStream
2020-04-15
spark

002.Spark Sql
spark sql-hello world1.引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
2.exmple程序
public class Man implements Serializable{
private static final long serialVersionUID = 1L;
private String name;
private String age;
Man(String name,String age){
this.name = name;
this.age = age;
}
pu
2020-04-12
spark
001.Spark RDD
spark-hello world1.创建maven项目spark-note,添加Spark依赖,新建TestSpark.java类2.引入依赖和打包插件
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</g
2020-04-09
spark
000.Spark Basement
Launching Applications with spark-submit./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
./bin/spark-submit \
--name "My app" \
--master local[4] \
--conf spark.eventLog.enabled=false \
--conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps" \
--con
2020-04-08
spark


卷积操作汇总
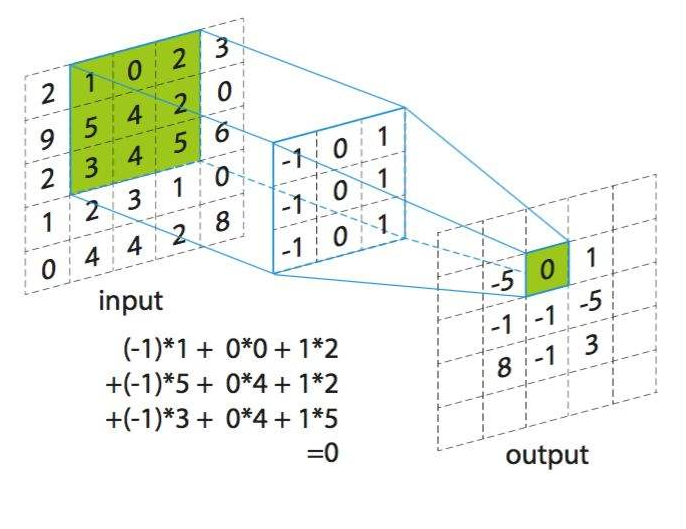
概念1.卷积核(Kernel):滤波矩阵,普遍的卷积核大小为3×3、5×5;2.步长(Stride):卷积核遍历特征图时每步移动的像素个数;3.填充(Padding):对特征图边界外进行填充(一般填充为0);4.通道(Channel):卷积层的通道数(层数);
标准卷积单通道多通道
3维卷积
1x1卷积
反卷积(转置卷积)将卷积核转换为稀疏矩阵后进行转置计算如下图,在2x2的输入图像上应用步长为1、边界全0填充的3x3卷积核,进行转置卷积(反卷积)计算
空洞卷积(膨胀卷积)
可分离卷积(Separable Convolutions)将卷积核分解为两项独立的核分别进行操作分解后的卷积计算过程如下图,先用3x1的卷积核作横向扫描计算,再用1x3的卷积核作纵向扫描计算
深度可分离卷积(Depthwise Separable Convolutions)3个卷积核分别对输入层的3个通道作卷积计算并堆叠在一起再使用1x1的卷积(3个通道)进行计算,得到只有1个通道的结果重复多次1x1的卷积操作(如下图为128次)
分组卷积(Grouped Convolution)在分组卷积中,卷积核被分成不同的组
2020-03-31
深度学习
elasticsearch 教程
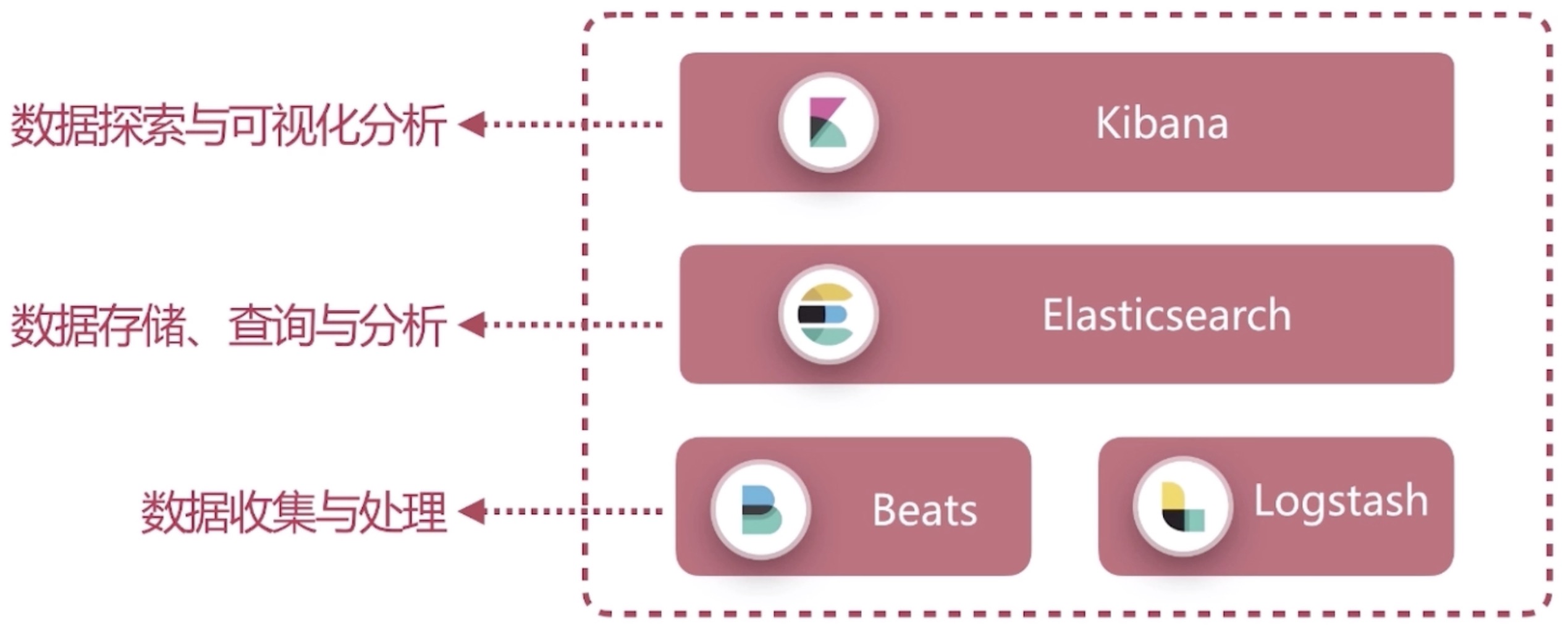
elasticsearch 教程
安装、启动、测试elasticsearch下载地址:https://www.elastic.co/cn/downloads/elasticsearch
kibana下载地址:https://www.elastic.co/cn/downloads/kibana
启动
./elasticsearch-7.5.1/bin/elasticsearch #浏览器访问:localhost:9200
{
"name" : "jiaopandeMacBook-Pro.local",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "5vku_94_SjevMGVYIo3RYg",
"version" : {
"number" : "7.5.1",
"build_flavor" : &q
2019-12-30
笔记
elasticsearch