spark streaming-hello world
note:http://spark.apache.org/docs/latest/streaming-programming-guide.html
- 引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.5</version>
</dependency>
安装 Netcat 下载地址:http://netcat.sourceforge.net/
解压-启动
$ nc -lk 9999
- example
SparkConf conf = new SparkConf().setAppName("spark streaming").setMaster("local[*]");
JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5));//5s处理一次
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("localhost",9999);
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
wordCounts.print();
jsc.start(); // Start the computation
jsc.awaitTermination();
jsc.close();
- example实时数据解析过程

-------------------------------------------
Time: 1586927760000 ms
-------------------------------------------
(jp,1)
(jiaopan,2)
(spark,2)
Time: 1586927710000 ms
-------------------------------------------
(hive,2)
Kafka
- 引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
- example
SparkConf conf = new SparkConf().setAppName("spark streaming").setMaster("local[*]");
JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5));
//kafka配置
List<String> topics = Arrays.asList("user_data_topic".split(","));
Map<String,Object> config = new HashMap<String, Object>();
config.put("bootstrap.servers","localhost:6667");
config.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
config.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
config.put("auto.offset.reset","earliest");
config.put("group.id","group.demo.sys.smvp-998");
JavaInputDStream<ConsumerRecord<String, String>> kafkaDStream = KafkaUtils.createDirectStream(jsc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, config));
JavaDStream<String> content = kafkaDStream.map(item->item.value());
content.print();
jsc.start(); // Start the computation
jsc.awaitTermination();
jsc.close();
-------------------------------------------
Time: 1586933770000 ms
-------------------------------------------
{"opType":0,"token":"interface_6b","content":[{"id":"5bcfc4f9","user_id":140050,"in_time":"2020-04-07 09:35:04","act_code":"order","act_value":4}]}
{"opType":0,"token":"interface_c6","content":[{"id":"dcb14f5a","user_id":0,"in_time":"2020-04-07 21:46:48","act_code":"","act_value":0}]}
Structured Streaming
note:http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
SparkSession spark = SparkSession
.builder()
.master("local[*]")
.appName("JavaStructuredNetworkWordCount")
.getOrCreate();
Dataset<Row> lines = spark.readStream().format("socket").option("host", "localhost").option("port", 9999).load();
StreamingQuery query = lines.writeStream().format("console").outputMode(OutputMode.Append()).start();
query.awaitTermination();
(base) jiaopandeMacBook-Pro:~ jiaopan$ nc -lk 9999
spark i love
-------------------------------------------
Batch: 1
-------------------------------------------
+------------+
| value|
+------------+
|spark i love|
+------------+
SparkSession spark = SparkSession
.builder()
.master("local[*]")
.appName("JavaStructuredNetworkWordCount")
.getOrCreate();
Dataset<Row> lines = spark.readStream().format("socket").option("host", "localhost").option("port", 9999).load();
Dataset<String> words = lines.as(Encoders.STRING()).flatMap(line -> Arrays.asList(line.split(" ")).iterator(), Encoders.STRING());
Dataset<Row> wordCount = words.groupBy("value").count();
StreamingQuery query = wordCount.writeStream().outputMode(OutputMode.Complete()).format("console").start();
query.awaitTermination();
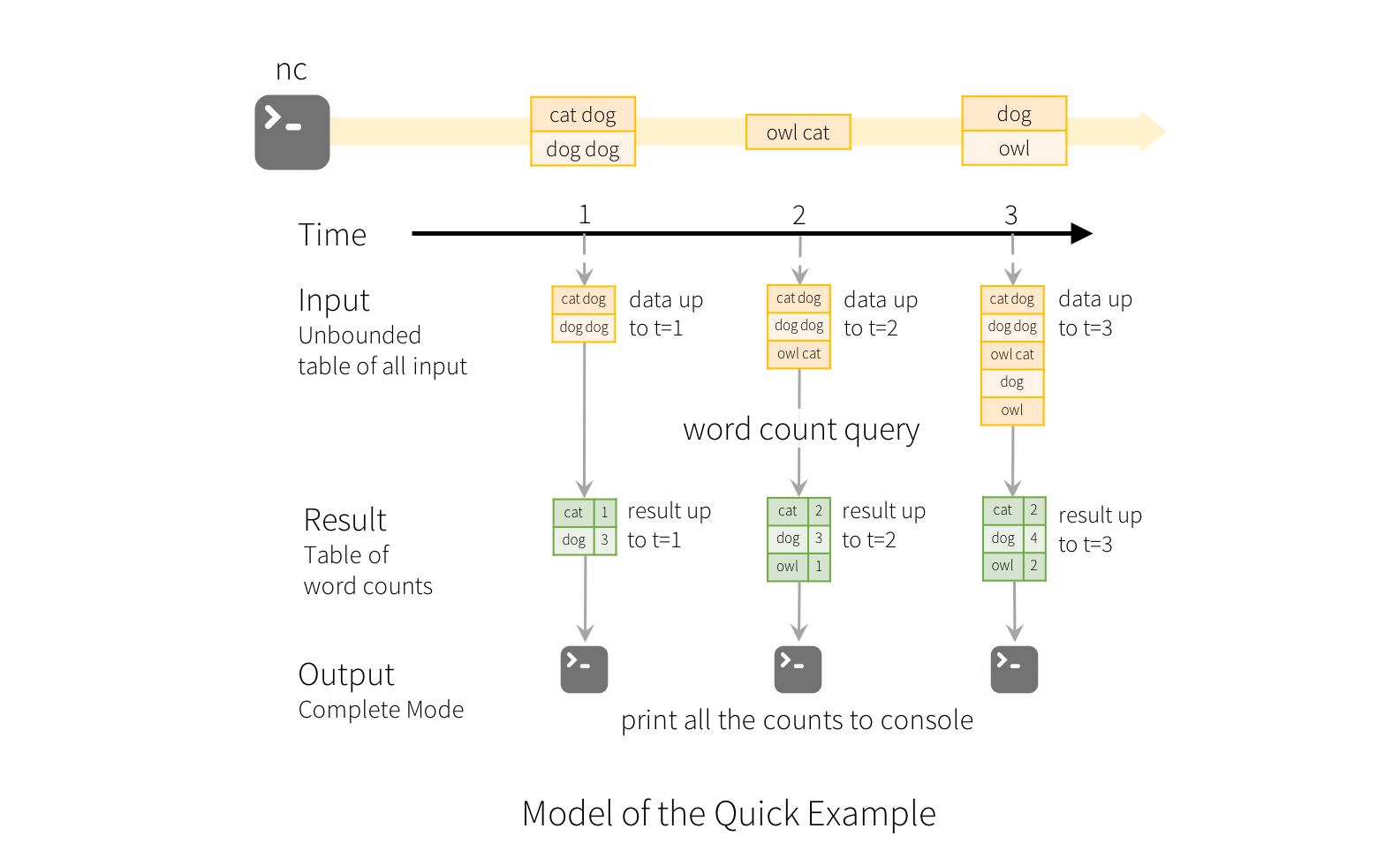
(base) jiaopandeMacBook-Pro:~ jiaopan$ nc -lk 9999
cat dog
+-----+-----+
|value|count|
+-----+-----+
| dog| 1|
| cat| 1|
+-----+-----+
(base) jiaopandeMacBook-Pro:~ jiaopan$ nc -lk 9999
...
cat dog owl
+-----+-----+
|value|count|
+-----+-----+
| dog| 2|
| cat| 2|
| owl| 1|
+-----+-----+
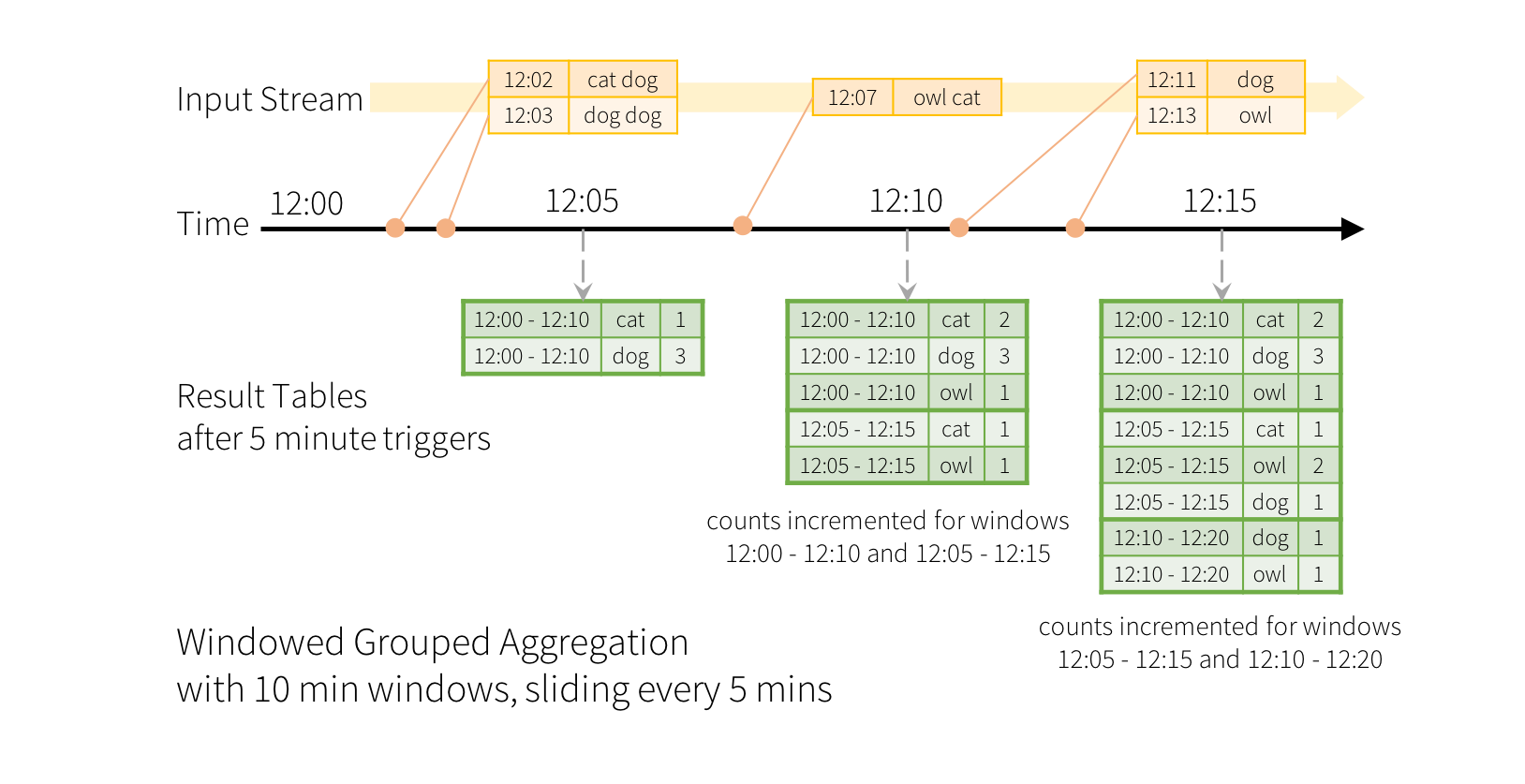
Window Operations on Event Time
SparkSession spark = SparkSession
.builder()
.master("local[*]")
.appName("JavaStructuredNetworkWordCount")
.getOrCreate();
spark.sparkContext().setLogLevel("WARN");
Dataset<Row> lines = spark.readStream().format("socket")
.option("host", "localhost").option("port", 9999)
.option("includeTimestamp",true).load();
Dataset<Row> words = lines.as(Encoders.tuple(Encoders.STRING(), Encoders.TIMESTAMP())).flatMap(
(FlatMapFunction<Tuple2<String, Timestamp>, Tuple2<String, Timestamp>>) item -> {
List<Tuple2<String, Timestamp>> result = new ArrayList<>();
for (String word : item._1.split(" ")) {
result.add(new Tuple2<>(word, item._2));
}
return result.iterator();
}, Encoders.tuple(Encoders.STRING(), Encoders.TIMESTAMP())).toDF("word", "timestamp");
Dataset<Row> windowedCounts = words.groupBy(
//<window duration> 计算window duration时间范围内的数据
//<slide duration> 数据更新周期,
functions.window(words.col("timestamp"), "20 seconds", "10 seconds"),
words.col("word")
).count().orderBy("window");
StreamingQuery query = windowedCounts.writeStream()
.outputMode(OutputMode.Complete())
.option("truncate", "false")
.format("console").start();
query.awaitTermination();
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2020-04-23 11:02:00, 2020-04-23 11:02:20]|cat |1 |
|[2020-04-23 11:02:00, 2020-04-23 11:02:20]|dog |1 |
|[2020-04-23 11:02:10, 2020-04-23 11:02:30]|dog |1 |
|[2020-04-23 11:02:10, 2020-04-23 11:02:30]|cat |1 |
+------------------------------------------+----+-----+
-------------------------------------------
Batch: 2
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2020-04-23 11:02:00, 2020-04-23 11:02:20]|cat |1 |
|[2020-04-23 11:02:00, 2020-04-23 11:02:20]|dog |1 |
|[2020-04-23 11:02:10, 2020-04-23 11:02:30]|dog |1 |
|[2020-04-23 11:02:10, 2020-04-23 11:02:30]|cat |1 |
|[2020-04-23 11:02:20, 2020-04-23 11:02:40]|cat |1 |
|[2020-04-23 11:02:20, 2020-04-23 11:02:40]|dog |2 |
|[2020-04-23 11:02:30, 2020-04-23 11:02:50]|dog |2 |
|[2020-04-23 11:02:30, 2020-04-23 11:02:50]|cat |1 |
+------------------------------------------+----+-----+
Output Sinks
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
writeStream
.foreach(...)
.start()
writeStream
.format("console")
.start()
writeStream
.format("memory")
.queryName("tableName")
.start()
Kafka
note:http://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
- 引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
- example
SparkSession session = SparkSession
.builder()
.master("local[*]")
.appName("JavaStructuredNetworkWordCount")
.getOrCreate();
session.sparkContext().setLogLevel("WARN");
Dataset<Row> dataset = session.readStream().format("kafka")
.option("kafka.bootstrap.servers", "localhost:6667")
.option("startingOffsets", "earliest")
.option("subscribe","test_topic")
.option("group.id", "group.demo.sys").load()
.selectExpr("CAST(value AS STRING)");
StreamingQuery query = dataset.writeStream().format("console").start();
query.awaitTermination();
-------------------------------------------
Batch: 0
-------------------------------------------
+--------------------+
| value|
+--------------------+
|{"content":[{"all...|
|{"content":[{"all...|
|{"url":"wlztk_sh_...|
|{"url":"wlztk_sh_...|
|{"url":"wlztk_sh_...|
|{"content":[{"all...|
|{"url":"wlztk_sh_...|
+--------------------+
only showing top 20 rows
Dataset<Row> df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
// Subscribe to multiple topics
Dataset<Row> df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
// Subscribe to a pattern
Dataset<Row> df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
Dataset<Row> df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load();
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
// Subscribe to multiple topics, specifying explicit Kafka offsets
Dataset<Row> df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.option("startingOffsets", "{\"topic1\":{\"0\":23,\"1\":-2},\"topic2\":{\"0\":-2}}")
.option("endingOffsets", "{\"topic1\":{\"0\":50,\"1\":-1},\"topic2\":{\"0\":-1}}")
.load();
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
// Subscribe to a pattern, at the earliest and latest offsets
Dataset<Row> df = spark
.read()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load();
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!